Xin chào các bạn, cảm ơn các bạn đã quan tâm và quay lại Blog Mì AI. Hôm nay để tiếp nối chuỗi bài về Computer Vision mình xin guide cho các bạn một bài đơn giản , theo đúng phong cách Mì AI về vấn đề Nhận dạng Tiếng Việt, nhận dạng văn bản (Optical Charactor Recognition) nhé.
Đang xem: Sử dụng tesseract ocr là gì, nhận diện văn bản bằng tesseract
Đang xem: Tesseract ocr là gì
Về cách nhận dạng văn bản thì có nhiều cách tiếp cận lắm luôn, một số cách mà mình biết như sau:
Sử dụng Tesseract OCRTrain model bằng CNN + SVMTrain model CNN – RNN – CTC….
Mỗi cái lại có cái hay, cái dở riêng và yêu cầu khả năng lập trình khác nhau. Hôm nay mình sẽ chia sẻ với các bạn cách dùng Tesseract OCR cho đơn giản nhé. Hiện Tess đã có đến phiên bản 4.0 nên dùng khá ổn cho các nhu cầu thông thường (chữ viết tay là chịu nhé).
Thôi, bắt đầu ngay cho nóng nhé!
Như thường lệ, mình xin trình bày trước cấu trúc bài viết để các bạn có cái nhìn tổng quan. Bài viết sẽ gồm các phần
Phần 1. Chuẩn bị môi trường, cài đặt thư viện Tesseract OCRPhần 2. Cấu hình và thêm ngôn ngữ tiếng ViệtPhần 3. Viết code nhận dạng và tận hưởng
Phần 1. Chuẩn bị môi trường
Như thường lệ các bạn hãy tạo 1 thử mục gocnhintangphat.com_Tess_OCR lưu vào đâu đó trên ổ cứng nhé. Bây giờ các bạn cài đặt Tesseract OCR theo cách sau, tùy vào các bạn dùng OS gì (mình không recommend window nhé, dù vẫn chạy).
Với các bạn dùng MacOS: Chúng ta sẽ cài đặt bằng công cụ Homebrew nhé. Các bạn gõ lệnh sau:
brew install tesseract
Sau khi gõ xong các bạn đợi chạy lệnh hết là thành công!
Với các bạn dùng Linux: Các bạn sử dụng apt-get như sau:
sudo apt-get install tesseract-ocr
Sau đó cũng ngồi đợi cho nó chạy hết lệnh là okie.
Với các bạn sử dụng Window: Thì cái này mình không cài thử bao giờ nên các bạn theo guide của Tesseract. Tóm lại là các bạn tải file cài đặt tại đây https://github.com/UB-Mannheim/tesseract/wiki (nhớ chọn bản 32bit và 64 bit phù hợp với window của bạn).
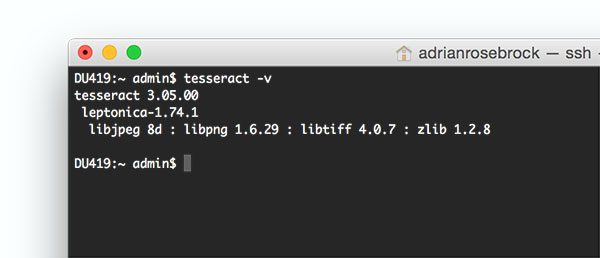
Okie rồi, sau khi cài đặt xong, các bạn có thể kiểm tra công cuộc cài đặt xem đã thành công chưa bằng cách gõ lệnh:
tesseract -v
Nếu như màn hình hiện ra thông tin phiên bản như ảnh dưới thì là bạn đã cài thành công.
Còn nếu như báo lỗi dạng “command not found” hoặc “is not recognize” thì các bạn restart lại máy hoặc đặt PATH cho phù hợp nhé (cái này tùy OS). Bạn nào cần thì comment mình sẽ guide thêm.
Xem thêm: Tuổi Thìn Là Con Gì ? Người Tuổi Thìn Sinh Năm Bao Nhiêu? Tuổi Thìn Là Con Gì
Phần 2. Cấu hình và cài đặt tiếng Việt.
Okie rồi, vậy là các bạn đã cài đặt thư viện Tess OCR. Tuy nhiên mặc định của nó không có ngôn ngữ tiếng việt và chúng ta phải tiến hành cài đặt thêm.
Các bạn truy cập vào link https://github.com/tesseract-ocr/tessdata chọn ngôn ngữ tiếng việt, chính là file vie.traineddata tải về máy và copy vào thư mục ngôn ngữ của Tess OCR.
Chắc các bạn sẽ hỏi thư mục ngôn ngữ ở đâu? Cái này nó tùy vào bạn cài đặt ở thư mục nào, hệ điều hình nào. Thư mục ngôn ngữ có tên tessdata nằm trong thư mục cài đặt Tesserac OCR. Nói chung là kiểu gì cũng có cái thư mục tên là tessdata trong máy, các bạn hãy tìm nó và copy file vie.traineddata vào thư mục tessdata đó.
Như máy mình là MacOS nên thư mục tessdata nó nằm ở:
root ▸ usr ▸ local ▸ Cellar ▸ tesseract ▸ 4.0.0_1 ▸ share
Phần 3. Viết code và tận hưởng thành quả nhận dạng
Xong phần cấu hình, bây giờ viết code bằng Python để nhận dạng nhé.
Xem thêm: ” Subdivision Là Gì – Nghĩa Của Từ Subdivision, Từ Subdivision Là Gì
Để code chạy được, các bạn hãy tiến hành cài đặt các thư viện sau:
pip install pillowpip install pytesseractpip install opencv-python
Bây giờ các bạn vào thư mục gocnhintangphat.com_Tess_Ocr và tải source trên github của mình (https://github.com/thangnch/py_ocr) về hoặc gõ lệnh sau:
git clone https://github.com/thangnch/py_ocr
Bây giờ trong thư mục gocnhintangphat.com_Tess_Ocr sẽ xuất hiện thêm thư mục py_ocr. File py_ocr.py nó làm gi thì mình đã comment từng dòng trong code rồi nhé. Còn bây giờ, tiến hành chuyển vào trong thư mục đó bằng lệnh cd py_ocr và gõ tiếp lệnh nhận dạng:
python py_ocr.py -i gocnhintangphat.com.png -p thresh
Nếu mọi thứ ngon lành, các bạn sẽ thấy kết quả nhận dạng tiếng việt mỹ mãn như sau. Nếu để ý các bạn sẽ thấy, file ảnh có nhiễu nhưng chúng ta vẫn nhận dạng vô tư nhé ;). Đó là vì mình có áp dụng biện pháp tiền xử lý ở đoạn ” -p thresh”

OK! Như vậy các bạn đã bước đầu dấn thân vào món OCR với nhận dạng tiếng việt. Món này còn nhiều thứ rất hay, mình sẽ tiếp tục chia sẻ trong những bài sau nhé.
Bài sau mình sẽ viết về cách train Tesseract OCR để nhận dạng các font chữ đặc thù. Ví dụ bạn có một văn bản với Font rất dị dạng thì Tess OCR sẽ không nhận được đâu, bạn phải train nó nhé!