Nhiều người nghĩ rằng, việc sử dụng Web Scraping để quét, đánh cắp dữ liệu là hành động xấu. Tuy nhiên, trong một số trường hợp, chủ dữ liệu muốn truyền tải dữ liệu đến càng nhiều người càng tốt, chúng lại mang tới lợi ích không ngờ. Chẳng hạn, website chính phủ cung cấp dữ liệu cho các website công cộng.
Đang xem: Phân biệt web scraping là gì, web scraping Được sử dụng Để làm gì?
Trong thời đại kỷ nguyên số như hiện nay, ai cũng biết rằng dữ liệu internet là một nguồn data dồi dào và phong phú nhất. Mà dữ liệu thì lại chẳng khác gì vàng cả. Người ta còn đo sự giàu có của một công ty dựa trên lượng dữ liệu mà công ty đó có cơ mà. Hãy thử điểm qua các công ty công nghệ xem họ có bao nhiêu dữ liệu?
Ví dụ như Facebook, Tiktok hay Twitter, hay như Zalo của Việt Nam. Mục tiêu hàng đầu của họ là tăng số lượng người dùng. Khi họ có nhiều người dùng (nhiều data đó) thì họ có thể dễ dàng kiếm tiền bằng quảng cáo. Vậy nên họ mới nói công ty to là công ty nắm trong tay nhiều dữ liệu chứ.

Trước tiên để có thể tranh luận thì bạn phải nắm sơ lược Web Crawling và Web Scraping là cái gì trước đã
Web Scrapinglà quá trình sử dụng bot để trích xuất nội dung và dữ liệu từ một trang web. Chúng được biết đến với nhiều tên gọi khác như web data mining (khai thác dữ liệu web) hoặc web harvesting. Thông thu thập được sẽ được xuất thành định dạng hữu ích hơn cho người dùng. Có thể là bảng tính hoặc API.
Trước đây, khi muốn thu thập dữ liệu, ta thường phải sao chép, lưu trữ một cách thủ công khá mất thời gian và công sức. Tuy nhiên, với Web Scraping, mọi thứ được tải xuống, trích xuất và sắp xếp, lưu trữ, phân tích một cách hoàn toàn tự động từ tất cả các nguồn trên internet theo yêu cầu của người thiết lập.
Được tích hợp nhiều tính năng tuyệt vời kể trên, giới chuyên môn đánh giá Web Scraping đang là công cụ hiệu quả nhất giúp thu thập dữ liệu từ Internet. Do vậy, việc công cụ này được sử dụng ngày càng phổ biến để sàng lọc thông tin là điều dễ hiểu.
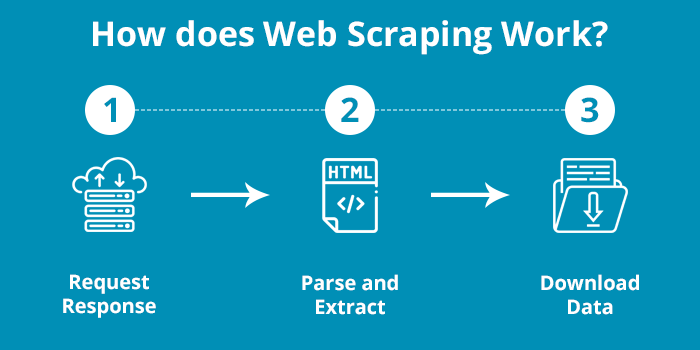
Đầu tiên, Web Scraping sẽ được cung cấp một hoặc nhiều URL để tải trước khi quét. Sau đó, công cụ này sẽ tải toàn bộ mã HTML cho trang đang đề cập. Thực hiện việc phân tích chuỗi HTML này để tìm ra vị trí chứa phần phát âm và hiển thị lên giao diện. Cuối cùng, trình quét web sẽ xuất ra tất cả dữ liệu đã được thu thập thành định dạng hữu ích hơn cho người dùng.
Hầu hết các trình dọn dẹp web sẽ xuất dữ liệu sang bảng tính CSV hoặc Excel, trong khi các trình dọn dẹp nâng cao hơn sẽ hỗ trợ các định dạng khác như JSON có thể được sử dụng cho API.
Web Crawlerlà phần mềm được thiết kế với mục đích có thể duyệt website trên mạng World Wide Web một cách có hệ thống, giúp thu thập thông tin của những trang web đó về cho công cụ tìm kiếm.
Việc này sẽ mang lại khả năng lưu chỉ mục các trang web đó vào bộ cơ sở dữ liệu của Search Engine. Đồng thời, giúp các công cụ tìm kiếm đó tìm ra những đánh giá chính xác nhất về website được thu thập dữ liệu.

Các module quan trọng của 1 crawler chi tiết hơn như sau:

Web Crawler có tính năng khám phá và tìm hiểu thông tin trên các trang web công khai hiện nay trên mạng WWW. Các công cụ thu thập thông tin hữu ích này sẽ lần lượt theo dõi các trang web và dò theo từng liên kết trên các trang đó.
Nó cũng giống như việc chúng ta duyệt từng nội dung có trên trang. Web Crawler thu thập dữ liệu trên các trang bằng việc lần lượt đi từ liên kết này tới liên kết khác và đưa các dữ liệu đó về cho máy chủ Search Engine.
Quá trình thu thập thông tin của phần mềm Web Crawler bắt đầu với một danh sách các địa chỉ website nào đó. Thông thường đó sẽ là danh sách các trang web được lưu từ những lần thu thập thông tin trước đó và danh sách do chủ sở hữu trang web gửi đến. Từ đó thu thập dữ liệu của tất cả các trang có liên quan, và đặc biệt ưu tiên các liên kết mới.

Phần mềm Web Crawler cũng xác định những trang web nào cần thu thập thông tin, tần suất trang cần tìm nạp từ mỗi trang web. Crawler hoạt động hoàn toàn tự động và ít chịu sự can thiệp bởi con người.
Sau khi thu thập đầy đủ tất cả thông tin, dữ liệu trang, các Crawler sẽ tổng hợp những dữ liệu đó với những dữ liệu ngoài trang như số lượng backlink trỏ đến website, lượng truy cập và gửi chúng về ngân hàng dữ liệu để được xét duyệt.
Web Crawling và Web Scraping là hai khái niệm có liên quan với nhau và có thể có nhiều người nhầm lẫn hoặc chưa phân biệt được sự khác nhau giữa hai khái niệm này. Web Crawling là quá trình thu thập thông tin từ các Website trên mạng Internet theo các đường links cho trước. Các Web Crawler sẽ truy cập các links này để download toàn bộ nội dung của trang web cũng như tìm kiếm thêm các đường links bên trong để tiếp tục truy cập và download nội dung từ các đường links này. Dữ liệu sau khi được tải về sẽ được đánh chỉ số (indexing) rồi lưu vào cơ sở dữ liệu.
Web Scaping cũng thực hiện việc tìm kiếm và thu thập thông tin nhưng khác với Web Crawling, Web Scraping không thu thập toàn bộ thông tin của một trang web mà chỉ thu thập những thông tin cần thiết, phù hợp với mục đích của người dùng. Trong WebScraping chúng ta cũng phần nào sử dụng WebCrawler để thu thập dữ liệu, kết hợp với Data Extraction (trích xuất dữ liệu) để tập trung vào các nội dung cần thiết.
Ví dụ như đối với trang amazon.com, Web Crawling sẽ thu thập toàn bộ nội dung của trang web này (tên các sản phẩm, thông tin chi tiết, bảng giá, hướng dẫn sử dụng, các reviews và comments về sản phẩm,…). Tuy nhiên Web Scaping có thể chỉ thu thập thông tin về giá của các sản phẩm để tiến hành so sánh giá này với các trang bán hàng online khác.
Điển hình như Google như bài viết trước mình cũng đã nhắc đến, nó sử dụng Crawl và Index, một con nhện chuyên dụng đi quét những thông tin
Hướng dẫn sử dụng tool cào (scraping) ebookTải tools trên github https://github.com/vuthanhnam94/scraping.ebookswww.youtube.com
vuthanhnam94/scraping.ebooksContribute to vuthanhnam94/scraping.ebooks development by creating an account on GitHub.
Xem thêm: Nghĩa Của Từ : Uniqueness Là Gì, Nghĩa Của Từ Uniqueness, Nghĩa Của Từ : Uniqueness
github.com
http://blog.ntechdevelopers.com/huong-dan-su-dung-tool-cao-scraping-ebooks/http://blog.ntechdevelopers.com/web-crawling-va-web-scraping-su-tranh-cai-giua-an-cap-tai-lieu-hay-la-mot-cong-nghe-thu-thap-du-lieu/”>
Nhiều người nghĩ rằng, việc sử dụng Web Scraping để quét, đánh cắp dữ liệu là hành động xấu. Tuy nhiên, trong một số trường hợp, chủ dữ liệu muốn truyền tải dữ liệu đến càng nhiều người càng tốt, chúng lại mang tới lợi ích không ngờ. Chẳng hạn, website chính phủ cung cấp dữ liệu cho các website công cộng.
Trong thời đại kỷ nguyên số như hiện nay, ai cũng biết rằng dữ liệu internet là một nguồn data dồi dào và phong phú nhất. Mà dữ liệu thì lại chẳng khác gì vàng cả. Người ta còn đo sự giàu có của một công ty dựa trên lượng dữ liệu mà công ty đó có cơ mà. Hãy thử điểm qua các công ty công nghệ xem họ có bao nhiêu dữ liệu?
Ví dụ như Facebook, Tiktok hay Twitter, hay như Zalo của Việt Nam. Mục tiêu hàng đầu của họ là tăng số lượng người dùng. Khi họ có nhiều người dùng (nhiều data đó) thì họ có thể dễ dàng kiếm tiền bằng quảng cáo. Vậy nên họ mới nói công ty to là công ty nắm trong tay nhiều dữ liệu chứ.
Trước tiên để có thể tranh luận thì bạn phải nắm sơ lược Web Crawling và Web Scraping là cái gì trước đã
Web Scrapinglà quá trình sử dụng bot để trích xuất nội dung và dữ liệu từ một trang web. Chúng được biết đến với nhiều tên gọi khác như web data mining (khai thác dữ liệu web) hoặc web harvesting. Thông thu thập được sẽ được xuất thành định dạng hữu ích hơn cho người dùng. Có thể là bảng tính hoặc API.
Trước đây, khi muốn thu thập dữ liệu, ta thường phải sao chép, lưu trữ một cách thủ công khá mất thời gian và công sức. Tuy nhiên, với Web Scraping, mọi thứ được tải xuống, trích xuất và sắp xếp, lưu trữ, phân tích một cách hoàn toàn tự động từ tất cả các nguồn trên internet theo yêu cầu của người thiết lập.
Được tích hợp nhiều tính năng tuyệt vời kể trên, giới chuyên môn đánh giá Web Scraping đang là công cụ hiệu quả nhất giúp thu thập dữ liệu từ Internet. Do vậy, việc công cụ này được sử dụng ngày càng phổ biến để sàng lọc thông tin là điều dễ hiểu.
Đầu tiên, Web Scraping sẽ được cung cấp một hoặc nhiều URL để tải trước khi quét. Sau đó, công cụ này sẽ tải toàn bộ mã HTML cho trang đang đề cập. Thực hiện việc phân tích chuỗi HTML này để tìm ra vị trí chứa phần phát âm và hiển thị lên giao diện. Cuối cùng, trình quét web sẽ xuất ra tất cả dữ liệu đã được thu thập thành định dạng hữu ích hơn cho người dùng.
Hầu hết các trình dọn dẹp web sẽ xuất dữ liệu sang bảng tính CSV hoặc Excel, trong khi các trình dọn dẹp nâng cao hơn sẽ hỗ trợ các định dạng khác như JSON có thể được sử dụng cho API.
Web Crawlerlà phần mềm được thiết kế với mục đích có thể duyệt website trên mạng World Wide Web một cách có hệ thống, giúp thu thập thông tin của những trang web đó về cho công cụ tìm kiếm.
Việc này sẽ mang lại khả năng lưu chỉ mục các trang web đó vào bộ cơ sở dữ liệu của Search Engine. Đồng thời, giúp các công cụ tìm kiếm đó tìm ra những đánh giá chính xác nhất về website được thu thập dữ liệu.
Web Crawler có tính năng khám phá và tìm hiểu thông tin trên các trang web công khai hiện nay trên mạng WWW. Các công cụ thu thập thông tin hữu ích này sẽ lần lượt theo dõi các trang web và dò theo từng liên kết trên các trang đó.
Nó cũng giống như việc chúng ta duyệt từng nội dung có trên trang. Web Crawler thu thập dữ liệu trên các trang bằng việc lần lượt đi từ liên kết này tới liên kết khác và đưa các dữ liệu đó về cho máy chủ Search Engine.
Quá trình thu thập thông tin của phần mềm Web Crawler bắt đầu với một danh sách các địa chỉ website nào đó. Thông thường đó sẽ là danh sách các trang web được lưu từ những lần thu thập thông tin trước đó và danh sách do chủ sở hữu trang web gửi đến. Từ đó thu thập dữ liệu của tất cả các trang có liên quan, và đặc biệt ưu tiên các liên kết mới.
Phần mềm Web Crawler cũng xác định những trang web nào cần thu thập thông tin, tần suất trang cần tìm nạp từ mỗi trang web. Crawler hoạt động hoàn toàn tự động và ít chịu sự can thiệp bởi con người.
Sau khi thu thập đầy đủ tất cả thông tin, dữ liệu trang, các Crawler sẽ tổng hợp những dữ liệu đó với những dữ liệu ngoài trang như số lượng backlink trỏ đến website, lượng truy cập và gửi chúng về ngân hàng dữ liệu để được xét duyệt.
Web Crawling và Web Scraping là hai khái niệm có liên quan với nhau và có thể có nhiều người nhầm lẫn hoặc chưa phân biệt được sự khác nhau giữa hai khái niệm này. Web Crawling là quá trình thu thập thông tin từ các Website trên mạng Internet theo các đường links cho trước. Các Web Crawler sẽ truy cập các links này để download toàn bộ nội dung của trang web cũng như tìm kiếm thêm các đường links bên trong để tiếp tục truy cập và download nội dung từ các đường links này. Dữ liệu sau khi được tải về sẽ được đánh chỉ số (indexing) rồi lưu vào cơ sở dữ liệu.
Web Scaping cũng thực hiện việc tìm kiếm và thu thập thông tin nhưng khác với Web Crawling, Web Scraping không thu thập toàn bộ thông tin của một trang web mà chỉ thu thập những thông tin cần thiết, phù hợp với mục đích của người dùng. Trong WebScraping chúng ta cũng phần nào sử dụng WebCrawler để thu thập dữ liệu, kết hợp với Data Extraction (trích xuất dữ liệu) để tập trung vào các nội dung cần thiết.
Ví dụ như đối với trang amazon.com, Web Crawling sẽ thu thập toàn bộ nội dung của trang web này (tên các sản phẩm, thông tin chi tiết, bảng giá, hướng dẫn sử dụng, các reviews và comments về sản phẩm,…). Tuy nhiên Web Scaping có thể chỉ thu thập thông tin về giá của các sản phẩm để tiến hành so sánh giá này với các trang bán hàng online khác.
Xem thêm: Số Cvv Là Gì – Cách Để Sử Dụng Mã Cvv
Điển hình như Google như bài viết trước mình cũng đã nhắc đến, nó sử dụng Crawl và Index, một con nhện chuyên dụng đi quét những thông tin
Hướng dẫn sử dụng tool cào (scraping) ebookTải tools trên github https://github.com/vuthanhnam94/scraping.ebookswww.youtube.com
vuthanhnam94/scraping.ebooksContribute to vuthanhnam94/scraping.ebooks development by creating an account on GitHub.github.com
http://blog.ntechdevelopers.com/huong-dan-su-dung-tool-cao-scraping-ebooks/http://blog.ntechdevelopers.com/web-crawling-va-web-scraping-su-tranh-cai-giua-an-cap-tai-lieu-hay-la-mot-cong-nghe-thu-thap-du-lieu/